컬렉션 프레임워크
컬렉션 프레임워크 (Collection Framework) 란
다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 인터페이스와 클래스의 집합을 의미한다. 즉, 데이터를 저장하는 자료구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것.
컬렉션 프레임워크의 인터페이스와 클래스는 굉장히 다양하므로 자세한 내용은 공식문서 를 참고하고 여기서는 자주 사용하는 인터페이스와 구현체에 대해서만 작성한다.
주요 인터페이스와 상속 관계
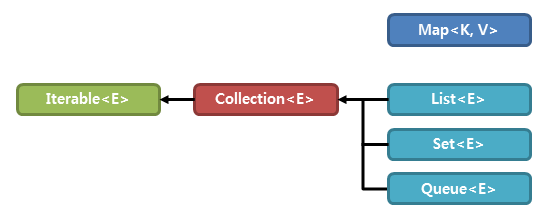
컬렉션 프레임워크의 핵심 인터페이스는 다음과 같다.
- List
- Set
- Map
List와 Set은 Collection 인터페이스를 상속 받지만 Map은 구조상의 차이로 인해 그 자체가 최상위 인터페이스이다. 그래서 Map은 진정한 컬렉션은 아님에도 불구하고 컬렉션을 조작할 수 있는 컬렉션 보기 작업이 포함되어 있다.
 출처 : tcpschool
출처 : tcpschool
주요 인터페이스와 구현체
| 인터페이스 | 설명 | 구현체 |
|---|---|---|
| List | - 순서 있음 - 중복 허용 | Vector, Stack, ArrayList, LinkedList 등 |
| Set | - 순서 없음 - 중복 비허용 | HashSet, TreeSet 등 |
| Map<K, V> | - 키와 값을 한 쌍으로 이루는 데이터 집합 - 순서 없음 - 키 중복 비허용 | Hashtable, Properties, HashMap, LinkedHashMap, TreeMap 등 |
Vector, Stack, Hashtable, Properties와 같은 클래스들은 컬렉션 프레임워크가 만들어지기 이전(JDK 1.2 이전)부터 존재하던 것이며, 기존의 컬렉션 클래스들과의 호환을 위해 설계를 변경해서 남겨뒀지만 가급적 사용하지 않는 것을 권장한다.
ArrayList
- 내부적으로 Object 배열을 이용해서 데이터를 순차적으로 저장한다. 기본 크기는 10
- 데이터를 순차적으로 저장하고 읽어올 때는 효율이 좋지만, 크기를 변경할 때 효율이 떨어진다.
- 다루는 데이터가 많을수록 중간에 데이터를 추가하거나 삭제할 때 시간이 오래 걸린다.
LinkedList
- 다루는 데이터가 많아도 중간에 데이터를 추가하거나 삭제하는 속도가 빠르다.
- ArrayList에 비해 데이터를 읽어오는 시간이 오래 걸린다.
Stack
- 마지막에 저장한 데이터를 가장 먼저 꺼내는 LIFO 구조. ArrayList와 같은 배열 기반의 컬렉션 클래스로 구현하는 것이 적합하다.
- 컬렉션 프레임워크가 만들어지기 이전부터 존재한 클래스로 Vector 클래스를 상속받아 구현되어 있다.
- 직접 구현하여 제공하고 있는 클래스로 new 키워드를 통해 객체를 생성할 수 있다.
Queue
- 처음에 저장한 데이터를 가장 먼저 꺼내게 되는 FIFO 구조. 처음에 저장한 데이터를 효율적으로 삭제하는 LinkedList로 구현하는 것이 적합하다.
- 인터페이스로 정의되어 있어 구현체를 이용해 객체를 생성해야 한다.
- PriorityQueue
- Queue의 구현체 중 하나로 저장한 순서와 상관없이 우선순위가 높은 데이터부터 꺼낸다.
- 힙 자료구조와 배열을 이용해 데이터를 저장한다.
- 객체를 저장할 때는 각 객체의 우선순위를 비교할 수 있는 방법을 클래스에 구현해둬야 한다.
- Deque
- 양쪽 끝에 데이터를 추가/삭제 하는 것이 가능하여 스택과 큐를 구현할 때 사용할 수 있다.
- Queue의 자식 인터페이스로 구현체로는 LinkedList, ArrayDeque 등이 있다.
HashSet
HashSet에 객체를 저장할 때 올바르게 중복을 제거하여 저장하려면 객체에 equals 메서드와 hashCode 메서드를 오버라이딩해야 한다.
오버라이딩해서 구현한 hashCode 메서드는 3가지 조건을 충족시켜야 한다.
- 동일한 객체의 hashCode 메서드를 호출하면 항상 같은 값이 반환되어야 한다.
- equals 메서드로 비교한 결과가 true 인 두 객체의 hashCode 메서드 반환 값은 반드시 같아야 한다.
- equals 메서드로 비교한 결과가 false 인 두 객체의 hashCode 메서드 반환 값은 다르도록 구현해야 해싱을 사용하는 컬렉션의 성능을 높일 수 있다.
TreeSet
- 이진 검색 트리라는 자료구조의 형태로 데이터를 저장한다.
- 정렬, 검색, 범위검색에 높은 성능을 보여주지만 데이터의 추가/삭제는 효율이 좋지 않다.
- TreeSet에 객체를 저장하려면 객체가 Comparable을 구현하거나 Comparator를 제공해서 객체를 비교할 수 있도록 해야한다.
HashMap
- 내부에
Entry라는 내부 클래스가 선언되어 있으며 Entry 배열을 이용해 데이터를 관리한다.
- 해싱이란
- 해시함수를 이용해서 데이터를 해시테이블에 저장하고 검색하는 기법이다.
해시함수로 해시테이블에 데이터가 저장된 위치를 알 수 있다.
같은 위치에 여러개의 값이 저장될 수 있지만 성능이 좋지 않다.
가능하면 객체는 고유한 해시함수 반환값을 갖도록 하는 것이 성능에 좋다.
Properties
- Hashtable 을 상속받아 구현한 클래스
- (String, String) 형태로 데이터를 저장한다.
- 애플리케이션의 환경설정과 관련된 속성을 저장하는데 사용된다.
Enumeration, Iterator, ListIterator
컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스로, Enumeration은 Iterator의 구버전이며 ListIterator는 Iterator의 기능을 향상 시킨 것으로 List 인터페이스를 구현한 컬렉션에서만 사용할 수 있다.
Iterator는 단방향으로만 이동할 수 있지만 ListIterator는 양방향으로의 이동이 가능하다.
Comparable 과 Comparator
Comparable 인터페이스를 구현한 클래스는 같은 타입의 객체끼리 서로 비교할 수 있으며 기본적으로 오름차순으로 구현한다.
오름차순이 아닌 별도의 기준으로 정렬하려면 Comparator 인터페이스를 구현한 구현체를 만들고 사용할 때 Arrays.sort 메서드의 두번째 인자로 넘겨주면 된다.